
. DOI: 10.48550/arxiv.2503.13335")
Assessing the progress of new AI language models can be as challenging as training them. Stanford researchers offer a new approach.
As new versions of artificial intelligence language models roll out with increasing frequency, many do so with claims of improved performance. Demonstrating that a new model is actually better than the last, however, remains an elusive and expensive challenge for the field.
Typically, to prove their mettle and improve trust that new models are indeed better, developers subject new models to a battery of benchmark questions. Potentially hundreds of thousands of such benchmark questions are stored in question banks, and the answers must be reviewed by humans, adding time and cost to the process.
Practical constraints make it impossible to ask every model every benchmark question, so developers choose a subset, introducing the risk of overestimating improvements based on softer questions. Stanford researchers have now introduced a cost-effective way to do these evaluations in a new paper presented at the International Conference on Machine Learning (ICML 2025). The study is available on the arXiv preprint server.
“The key observation we make is that you must also account for how hard the questions are,” said Sanmi Koyejo, an assistant professor of computer science in the School of Engineering who led the research. “Some models may do better or worse just by luck of the draw. We’re trying to anticipate that and adjust it to make fairer comparisons.”
“This evaluation process can often cost as much or more than the training itself,” added co-author Sang Truong, a doctoral candidate at the Stanford Artificial Intelligence Lab (SAIL). “We’ve built an infrastructure that allows us to adaptively select subsets of questions based on difficulty. It levels the playing field.”
Apples and oranges
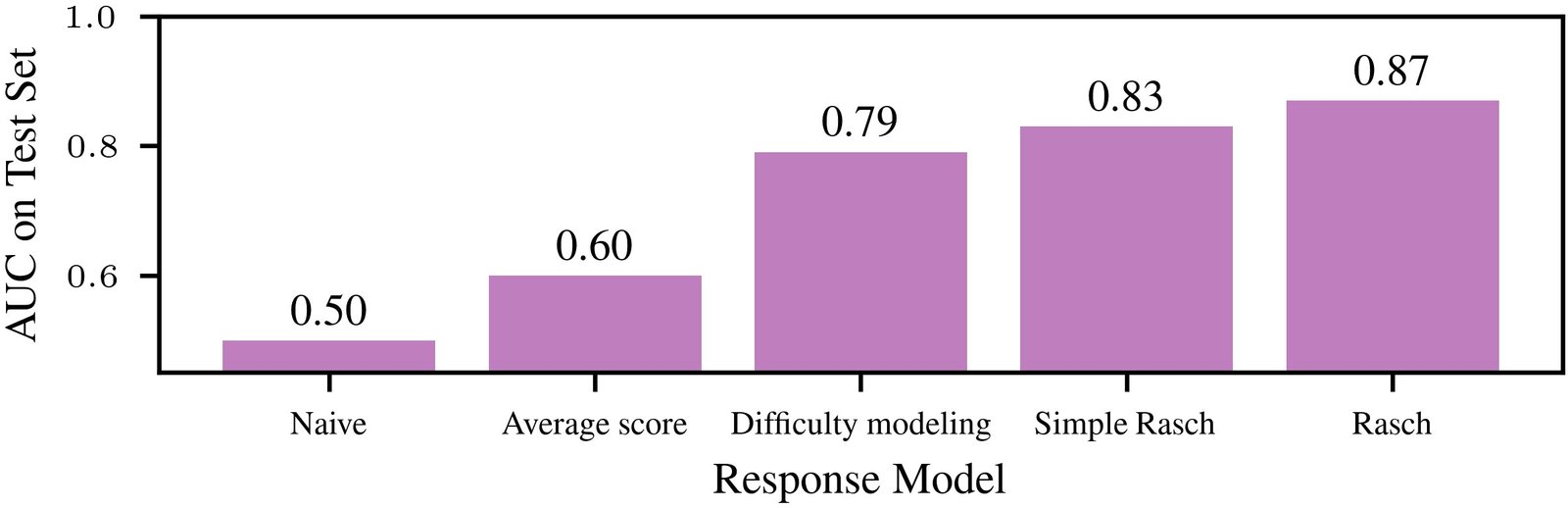
To achieve their goal, Koyejo, Truong, and colleagues have borrowed a decades-old concept from education, known as Item Response Theory, which takes into account question difficulty when scoring test-takers. Koyejo compares it to the way standardized tests like the SAT and other kinds of adaptive testing work. Every right or wrong answer changes the question that follows.
The researchers use language models to analyze questions and score them on difficulty, reducing the costs by half and in some cases by more than 80%. That difficulty score allows the researchers to compare the relative performance of two models.
To construct a large, diverse, and well-calibrated question bank in a cost-effective way, the researchers use AI’s generative powers to create a question generator that can be fine-tuned to any desired level of difficulty. This helps automate the replenishing of question banks and the culling of “contaminated” questions from the database.
Fast and fair
With better-designed questions, the authors say, others in the field can make better performance evaluations with a far smaller subset of queries. This approach is faster, fairer, and less expensive.
The new approach also works across knowledge domains—from medicine and mathematics to law. Koyejo has tested the system against 22 datasets and 172 language models and found that it can adapt easily to both new models and questions.
Their approach was able to chart subtle shifts in GPT 3.5’s safety over time, at first getting better and then retreating in several variations tested in 2023. Language model safety is a metric of how robust a model is to data manipulation, adversarial attacks, exploitation, and other risks.
Where once reliably evaluating language models was an expensive and inconsistent prospect, the new Item Response Theory approach puts rigorous, scalable, and adaptive evaluation within reach. For developers, this means better diagnostics and more accurate performance evaluations. For users, it means fairer and more transparent model assessments.
“And, for everyone else,” Koyejo said. “It will mean more rapid progress and greater trust in the quickly evolving tools of artificial intelligence.”
More information:
Sang Truong et al, Reliable and Efficient Amortized Model-based Evaluation, arXiv (2025). DOI: 10.48550/arxiv.2503.13335
arXiv
Stanford University
Citation:
New method makes AI language model evaluations faster, fairer, and less costly (2025, July 15)
retrieved 15 July 2025
from https://techxplore.com/news/2025-07-method-ai-language-faster-fairer.html
This document is subject to copyright. Apart from any fair dealing for the purpose of private study or research, no
part may be reproduced without the written permission. The content is provided for information purposes only.


{kind=link}