
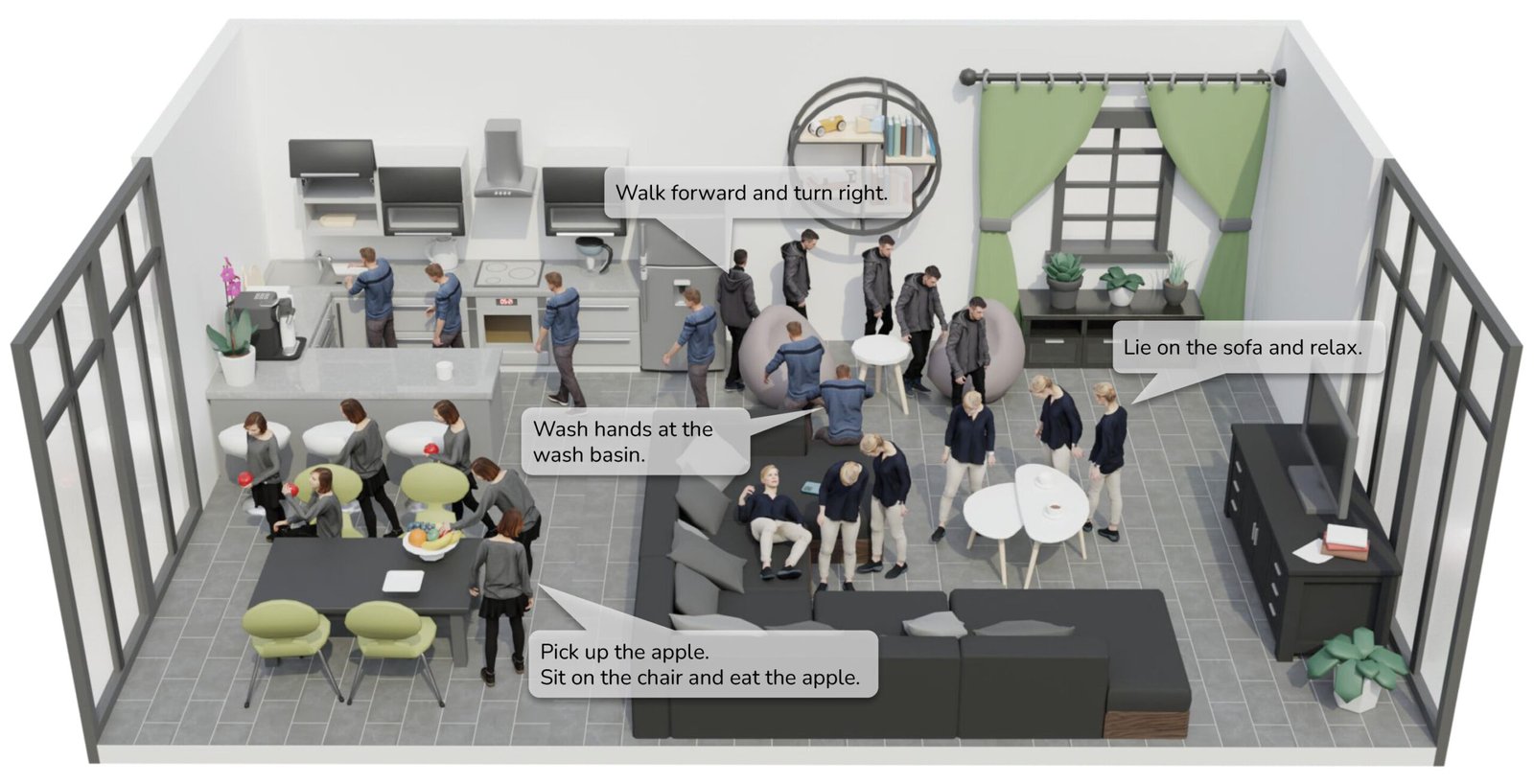

Artificial intelligence (AI) systems have become increasingly better at synthesizing images and videos showing humans, animals and objects. The automated generation of videos in which human characters engage in specific activities could have various valuable applications, for instance simplifying the creation of animated films, content for virtual reality (VR) and video games.
Researchers at Peking University, BIGAI, and Beijing University of Posts and Telecommunications developed a new computational framework to generate realistic motions for human characters navigating 3D environments.
This framework, introduced in a paper presented at the SIGGRAPH Asia 2024 Conference, relies on an auto-regression diffusion model to synthesize consecutive character motion segments and a scheduler that predicts transitions to the next set of movements.
“Our inspiration for this research emerged from observing the effortless and intuitive way humans interact with their daily environments,” Nan Jiang, co-author of the paper, told Tech Xplore.
“Whether it’s reaching for a coffee cup on a table or navigating around furniture, our movements flow seamlessly without conscious planning. This natural dynamism sparked an ambitious endeavor to revolutionize how virtual characters engage with their surroundings.”
Many AI-powered models for generating human motions have been found to generate plausible object interaction motions for virtual humanoid characters. However, to perform well, these models often require complex and user-defined inputs, such as predefined waypoints and stage transitions.
“This dependency on user-defined inputs not only complicates the user experience but also hampers the automation and fluidity of motion generation,” said Zimo He, co-author of the paper.
“Recognizing these limitations, our primary objective was to develop a comprehensive framework that simplifies this process. We aimed to create a system capable of autonomously generating natural, multi-stage, and scene-aware human motions using only straightforward text instructions and designated goal locations.”
The researchers set out to enhance the coherence and realism of model-generated motions, while also minimizing the need for complex user inputs. To achieve this, they also compiled the LINGO dataset, a new extensive collection of language-annotated motion capture data that could be used to train machine learning models.
“Our framework is designed to transform simple text instructions and a target location into realistic, multi-stage human motions within a 3D environment,” said Yixin Zhu, co-corresponding author of the paper. “At its core, the system integrates several innovative components that work harmoniously to achieve this transformation.”
The first component of the team’s framework is an auto-regressing diffusion model that generates sequential human motion segments. This process mirrors the process through which humans adjust their movements in real-time, enabling a smooth transition from one motion to the next.
“Building on our earlier work with TRUMANS, which utilized a voxel grid for scene representation, we have now advanced to a dual voxel scene encoder,” said Jiang.
“This enhancement provides the system with a comprehensive understanding of the environment by capturing both the current immediate surroundings and anticipating future spaces based on the goal location.”
The dual approach underlying the team’s framework ultimately allows characters to smoothly navigate 3D environments, interacting with objects and avoiding nearby obstacles. Notably, the framework also includes a frame-embedded text component.
“This encoder integrates the textual instruction with temporal information, meaning it not only understands what actions to perform but also when to perform them,” said Zimo. “This integration ensures that the generated motions align accurately with the intended actions described in the text, much like how humans naturally sequence their actions with perfect timing.”
Essentially, the goal encoder processes a character’s target location and any sub-goals it is expected to complete on the way, divided into distinct interaction stages. This step guides the character’s movements, directing it towards achieving desired goals.
“Complementing this is our autonomous scheduler, which functions as a ‘motion conductor,'” said Hongjie Li, co-author of the paper.
“It intelligently determines the optimal points to transition between different action stages, such as moving from walking to reaching or interacting. This ensures that the entire motion sequence flows seamlessly and naturally, without abrupt or unnatural transitions.”
The new framework developed by Jiang and his colleagues has various advantages over other models for character motion generation introduced in the past. Most notably, it simplifies the information that users need to feed the motion to generate coherent motions, limiting it to basic text instructions and the target location that a character should reach.

“By integrating scene awareness and temporal semantics, our system produces motions that are contextually appropriate and visually convincing,” said Siyuan Huang, co-corresponding author of the paper.
“Furthermore, the unified pipeline adeptly handles complex sequences of actions, maintaining continuity and minimizing unintended collisions within diverse and cluttered environments.”
In initial tests run by the researchers, their framework performed remarkably well, generating high-quality and coherent character motions with limited user inputs. The generated motions were found to be aligned both with the textual instructions provided by users and with the environmental context the virtual characters were navigating.
“This alignment was quantitatively validated through various metrics, where our approach demonstrated superior precision and significantly reduced instances of scene penetration compared to existing methods like TRUMANS,” said Jiang. “These advancements underscore the effectiveness of our framework in producing motions that are not only visually convincing but also contextually and spatially accurate.”
A further important contribution of this recent study is the introduction of the LINGO dataset, which could be used to train other algorithms. This dataset contains over 16 hours of motion sequences, spanning across 120 unique indoor scenes and demonstrating 40 distinct types of character-scene interactions.
“The LINGO dataset serves as a robust foundation for training and evaluating motion synthesis models, bridging the gap between natural language and motion data,” said Zimo.
“By providing detailed language descriptions alongside motion data, LINGO facilitates a deeper understanding of the interplay between human language, movement, and environmental interaction, thereby supporting and inspiring future research in this domain.”
Compared to the character motions created by previously introduced models, those generated by the team’s framework were found to be smoother and more natural. This is in great part due to its underlying motion synthesis components.
“By seamlessly integrating locomotion, hand-reaching, and human-object interactions into a single cohesive pipeline, our model achieves a level of coherence and fluidity in motion sequences that surpasses fragmented, stage-specific approaches,” said Li. “This integration not only streamlines the motion generation process but also enhances the overall realism and believability of the virtual characters’ interactions within their environments.”
The new framework introduced by Jiang, Zimo, and their colleagues could have various real-world applications. Firstly, it could simplify and support the generation of immersive content to be viewed using VR and AR technology.
“In the realm of virtual reality (VR) and augmented reality (AR), our framework can significantly enhance the realism and immersion of virtual characters, thereby improving user experiences,” said Li. “The gaming and animation industries stand to benefit immensely from our system, as it can automate the generation of diverse and realistic character animations, reducing the manual effort required and increasing the variety of in-game actions.”
The researchers’ framework could also be used to create personalized demonstration videos that guide users on how to complete sports and rehabilitation therapy exercises. These are videos that simulate the motions that the users need to perform, allowing them to complete exercises independently, without a human instructor present.
“In robotics and human-computer interaction, enabling robots to perform human-like movements and interact seamlessly within shared environments can tremendously improve collaborative tasks and efficiency,” said Zhu. “Additionally, our framework can be leveraged in assisted living and training simulations, developing realistic simulations for training purposes such as emergency response training or skill development in various professional fields.”

In the future, the framework and dataset introduced by Jiang and his colleagues could contribute to the further advancement of AI-based models for motion generation. Meanwhile, the researchers are working to further improve their approach, for instance by improving the physical accuracy of the motions it generates.
“While our current model excels in producing visually realistic movements, we aim to incorporate more nuanced physical properties such as gravity, friction, and balance,” said Jiang. “This refinement will ensure that the motions are not only believable in appearance but also physically plausible, thereby increasing their reliability and applicability in real-world scenarios.”
In their next studies, Jiang and their colleagues will also try to enhance the granularity of the motions generated by the model. Currently, their model concentrates on the body movements of characters, but eventually they would like it to also capture finer details, such as hand gestures and facial expressions.
“By integrating these elements, we hope to achieve even higher levels of realism and expressiveness in virtual characters, making their interactions more human-like and engaging,” said Zimo.
An additional aspect of the model that the team hopes to improve is its ability to generalize across a wider range of character-scene interactions. In addition, they would like the model to synthesize motions in real-time.
“The ability to generate motions instantaneously in response to dynamic inputs would be particularly beneficial for interactive applications such as live VR experiences and responsive gaming environments,” said Zi Wang. “Achieving real-time capabilities would significantly broaden the practical usability of our framework, making it more adaptable to real-world interactive demands.”
In their next studies, the researchers also plan to integrate multi-modal inputs in their framework. This would allow users to interact with virtual characters in more engaging ways.
“By incorporating additional input modalities such as speech and gestures, we aim to create a more comprehensive and intuitive interface for motion synthesis,” said Yixin Chen. “This multi-modal approach would allow users to interact with virtual characters in a more natural and seamless manner, enhancing the overall user experience.”
A final objective for Jiang, Zimo, and their colleagues will be to ensure that their model is both scalable and energy efficient, particularly as the complexity of the interactions it generates increases. This could facilitate its real-world deployment, ensuring that its performance and efficiency is good even while tackling computationally demanding tasks.
“Through these research endeavors, we aspire to push the boundaries of autonomous human motion synthesis, making it increasingly effective and versatile across various industries and applications,” added Zhu. “We are excited about the future potential of our work and look forward to contributing further advancements to this dynamic field.”
More information:
Nan Jiang et al, Autonomous character-scene interaction synthesis from text instruction, SIGGRAPH Asia Conference Papers (2024). pku.ai/publication/hoi2024siggraphasia/
© 2024 Science X Network
Citation:
Computational framework simplifies synthesized motions for human characters in 3D environments (2024, November 5)
retrieved 5 November 2024
from https://techxplore.com/news/2024-11-framework-motions-human-characters-3d.html
This document is subject to copyright. Apart from any fair dealing for the purpose of private study or research, no
part may be reproduced without the written permission. The content is provided for information purposes only.


{kind=link}