

Artificial intelligence (AI) models are constantly contending to crush performance benchmarks that gauge their skills. But these models have been slow to surpass AI “IQ” tests that move beyond memorizing, reasoning, and recognizing patterns to measuring the more profound humanlike facets of intelligence, such as the ability to learn in real time.
One of these more difficult benchmarks is the Abstraction and Reasoning Corpus (ARC) for artificial general intelligence (AGI) introduced by AI researcher and Google senior staff software engineer François Chollet in 2019. The ARC-AGI benchmark measures the efficiency of AI systems to acquire new skills outside of their training data. Chollet considers the ability to efficiently aquire new skills a mark of AGI.Since its inception, however, the ARC-AGI’s success rate has been lagging—from an already low 21 percent in 2020 to just 30 percent in 2023.
To jumpstart renewed progress, Chollet and Mike Knoop, cofounder of workflow automation software Zapier, are hosting the ARC Prize. The contest challenges entrants to build an open-source solution that dominates the ARC-AGI benchmark, with a pool of more than US $1 million in prize money. A $500,000 grand prize will be split among the top five teams that achieve at least 85 percent performance, while $45,000 will be granted to the submitted research paper that best furthers the understanding of how to attain high performance on ARC-AGI.
“LLMs are not by themselves intelligent—they’re more like a way to store and retrieve knowledge, which is a component of intelligence, but it is not all there is.” —François Chollet, Google


“Every other AI benchmark out there assumes that the task is fixed and you can prepare for it in advance. What makes this competition special is that it is the only AI benchmark with an emphasis on the ability to understand a new task on the fly,” says Chollet.
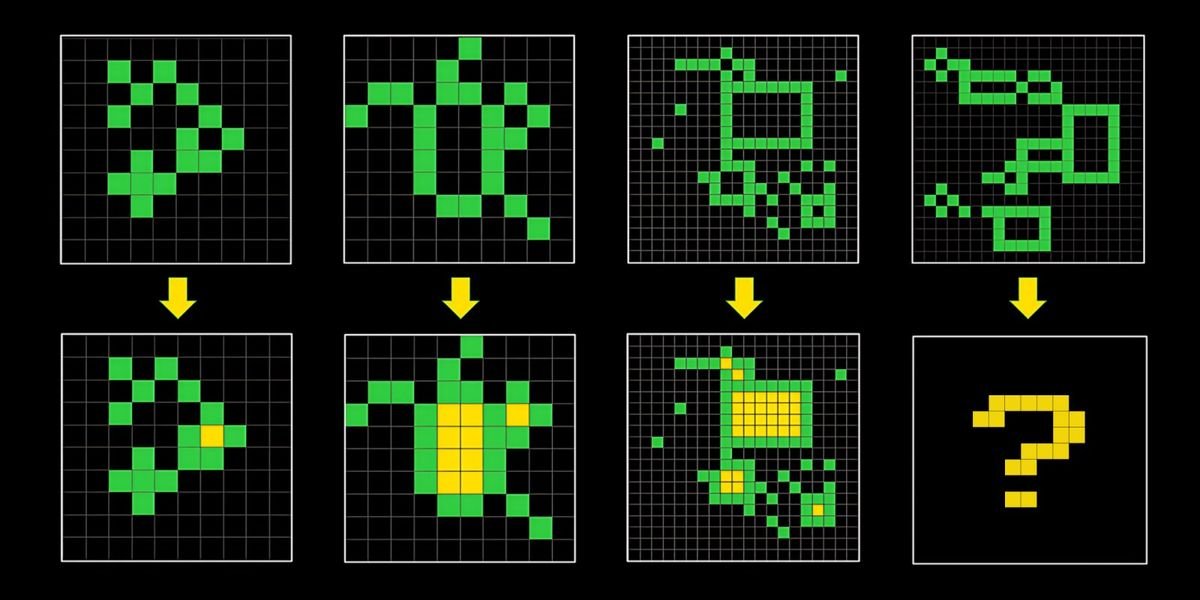
Contenders must craft an AI model that solves a set of 100 visual puzzles. Each puzzle presents a new task, with a handful of grid pairs that demonstrate sample inputs and their corresponding outputs. The model should be able to infer the rule that produces a certain output based on the input and apply it to a final grid with only the input shown. This type of puzzle perplexes AI systems because they’re more attuned to memorizing a program template for solving a problem rather than adapting to tasks they haven’t been trained on.
The ARC Prize has a training dataset and a testing dataset, both of which are public. However, the evaluation dataset assessing model performance is private, so models can’t be trained on it. Submissions also won’t have Internet access, so solutions must be able to run offline, adding another layer of difficulty.
Some approaches Chollet has seen from contestants so far encompass two broad categories: domain-specific language (DSL) program synthesis and fine-tuning large language models (LLMs). The first approach entails developing a programming language with functions for common concepts in ARC tasks—such as mirroring, rotation, symmetry, and other grid transformations—and combining these functions into programs that can potentially solve a task. The AI model then performs a discrete program search to find a likely solution, sometimes selecting the shortest or simplest one. Meanwhile, LLM-focused methods are either trained on code and then fine-tuned on tokenized representations of ARC tasks or are fine-tuned during test time.
“I think the brand of approach that’s going to be the most promising is to merge discrete program search and LLM-based search into one thing,” Chollet says. “The key is to do program search but leverage some sort of intuition over the space of possible programs and tasks.”
“I think [artificial general intelligence] is an undefinable concept, and I don’t think we would ever be able to coherently define it.” —Julian Togelius, New York University
Ultimately, the ARC Prize is trying to accelerate AGI research through fresh ideas and innovative open-source solutions, as well as speed up the timeline for AGI.
“Right now we’re stuck in this LLM-only world,” says Chollet. “But LLMs are not by themselves intelligent—they’re more like a way to store and retrieve knowledge, which is a component of intelligence, but it is not all there is.”
What makes human intelligence unique and general, according to Chollet, is the ability to adapt to novelty and learn in the moment. “This is the essence of intelligence. We’re not general because we’ve been trained on a million different tasks—we are general because if you give us a brand new task, we can figure it out quickly. And that’s exactly what the ARC Prize is trying to solve,” he adds.
Julian Togelius, an associate professor of computer science and engineering at New York University and author of the upcoming book Artificial General Intelligence, agrees that there exists “a bit of a monoculture. We’re using the same few architectures all the time.” He believes the ARC Prize can diversify the techniques for AGI. “I think ARC is cool. I think it’s beautiful and interesting that standard deep learning architectures and methods like LLMs do badly at it,” he says.
But Togelius is skeptical that solving the ARC Prize would mean having reached AGI. “I think it’s an undefinable concept, and I don’t think we would ever be able to coherently define it,” he says. “It’s entirely possible to imagine that you would have come up with software that could solve the ARC Prize and not really be good at anything else.”
Togelius is quick to note, though, that AGI is here to stay and researchers will continue aiming for it. “What’s going to happen is that bit by bit we can solve more problems,” he says. “By conquering each of these abilities, we’re trying to get to the core of intelligence.”
From Your Site Articles
Related Articles Around the Web






{kind=link}