


Times change, and so must benchmarks. Now that we’re firmly in the age of massive generative AI, it’s time to add two such behemoths,
Llama 2 70B and Stable Diffusion XL, to MLPerf’s inferencing tests. Version 4.0 of the benchmark tests more than 8,500 results from 23 submitting organizations. As has been the case from the beginning, computers with Nvidia GPUs came out on top, particularly those with its H200 processor. But AI accelerators from Intel and Qualcomm were in the mix as well.
MLPerf started pushing into the LLM world
last year when it added a text summarization benchmark GPT-J (a 6 billion parameter open-source model). With 70 billion parameters, Llama 2 is an order of magnitude larger. Therefore it requires what the organizer MLCommons, a San Francisco-based AI consortium, calls “a different class of hardware.”


“In terms of model parameters, Llama-2 is a dramatic increase to the models in the inference suite,”
Mitchelle Rasquinha, a software engineer at Google and co-chair of the MLPerf Inference working group, said in a press release.
Stable Diffusion XL, the new
text-to-image generation benchmark, comes in at 2.6 billion parameters, less than half the size of GPT-J. The recommender system test, revised last year, is larger than both.
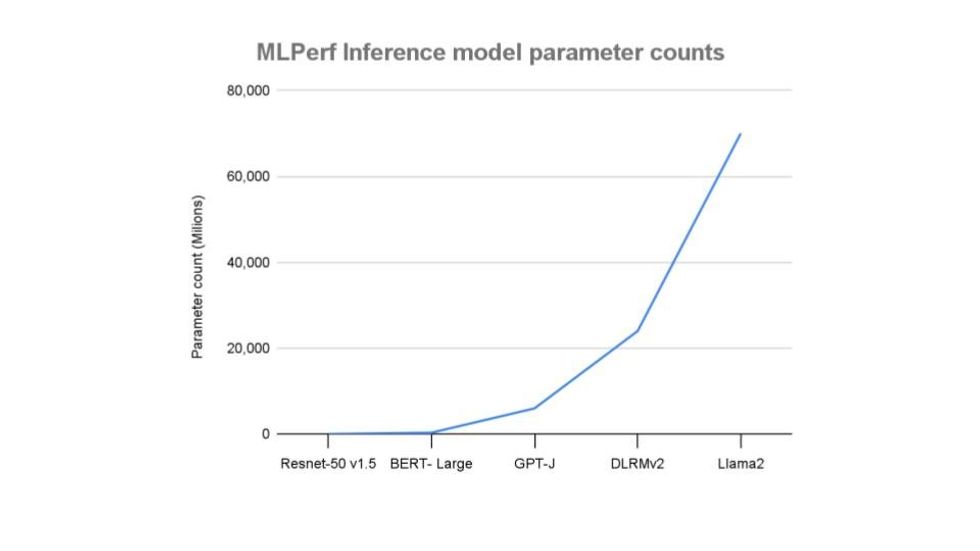 MLPerf benchmarks run the range of sizes, with the latest, such as Llama 2 70B in the many tens of billions of parameters.MLCommons
MLPerf benchmarks run the range of sizes, with the latest, such as Llama 2 70B in the many tens of billions of parameters.MLCommons
The tests are divided between systems meant for use in
data centers and those intended for use by devices out in the world, or the “edge” as its called. For each benchmark, a computer can be tested in what’s called an offline mode or in a more realistic manner. In offline mode, it runs through the test data as fast as possible to determine its maximum throughput. The more realistic tests are meant to simulate things like a stream of data coming from a camera in a smartphone, multiple streams of data from all the cameras and sensors in a car, or as queries in a data center setup, for example. Additionally, the power consumption of some systems was tracked during tasks.
Data center inference results
The top performers in the new generative AI categories was an Nvidia H200 system that combined eight of the GPUs with two Intel Xeon CPUs. It managed just under 14 queries per second for Stable Diffusion and about 27,000 tokens per second for Llama 2 70B. Its nearest competition were 8-GPU H100 systems. And the performance difference wasn’t huge for Stable Diffusion, about 1 query per second, but the difference was larger for Llama 2 70B.
H200s are the same
Hopper architecture as the H100, but with about 75 percent more high-bandwidth memory and 43 percent more memory bandwidth. According to Nvidia’s Dave Salvator, memory is particularly important in LLMs, which perform better if they can fit entirely on the chip with other key data. The memory difference showed in the Llama 2 results, where H200 sped ahead of H100 by about 45 percent.
According to the company, systems with H100 GPUs were 2.4-2.9 times faster than H100 systems from the
results of last September, thanks to software improvements.
Although H200 was the star of Nvidia’s benchmark show, its newest GPU architecture,
Blackwell, officially unveiled last week, looms in the background. Salvator wouldn’t say when computers with that GPU might debut in the benchmark tables.
For its part,
Intel continued to offer its Gaudi 2 accelerator as the only option to Nvidia, at least among the companies participating in MLPerf’s inferencing benchmarks. On raw performance, Intel’s 7-nanometer chip delivered a little less than half the performance of 5-nm H100 in an 8-GPU configuration for Stable Diffusion XL. Its Gaudi 2 delivered results closer to one-third the Nvidia performance for Llama 2 70B. However, Intel argues that if you’re measuring performance per dollar (something they did themselves, not with MLPerf), the Gaudi 2 is about equal to the H100. For Stable Diffusion, Intel calculates it beats H100 by about 25 percent on performance per dollar. For Llama 2 70B it’s either an even contest or 21 percent worse, depending on whether you’re measuring in server or offline mode.
Gaudi 2’s successor, Gaudi 3 is expected to arrive later this year.
Intel also touted several CPU-only entries that showed a reasonable level of inferencing performance is possible in the absence of a GPU, though not on Llama 2 70B or Stable Diffusion. This was the first appearance of Intel’s 5th generation Xeon CPUs in the MLPerf inferencing competition, and the company claims a performance boost ranging from 18 percent to 91 percent over 4th generation Xeon systems from September 2023 results.
Edge inferencing results
As large as it is, Llama 2 70B wasn’t tested in the edge category, but Stable Diffusion XL was. Here the top performer was a system using two Nvidia L40S GPUs and an Intel Xeon CPU. Performance here is measured in latency and in samples per second. The system, submitted by Taipei-based cloud infrastructure company
Wiwynn, produced answers in less than 2 seconds in single-stream mode. When driven in offline mode, it generates 1.26 results per second.
Power consumption
In the data center category, the contest around energy efficiency was between Nvidia and Qualcomm. The latter has focused on energy efficient inference since introducing the Cloud AI 100 processor more than a year ago. Qualcomm introduced a new generation of the accelerator chip the Cloud AI 100 Ultra late last year, and its first results showed up in the edge and data center performance benchmarks above. Compared to the Cloud AI 100 Pro results, Ultra produced a 2.5 to 3 times performance boost while consuming less than 150 Watts per chip.
Among the edge inference entrance, Qualcomm was the only company to attempt Stable Diffusion XL, managing 0.6 samples per second using 578 watts.
From Your Site Articles
Related Articles Around the Web






{kind=link}