
Indian AI lab Sarvam on Tuesday unveiled a new generation of large language models, as it bets that smaller, efficient open-source AI models will be able to grab some market share away from more expensive systems offered by its much larger U.S. and Chinese rivals.
The launch, announced at the India AI Impact Summit in New Delhi, aligns with New Delhi’s push to reduce reliance on foreign AI platforms and tailor models to local languages and use cases.
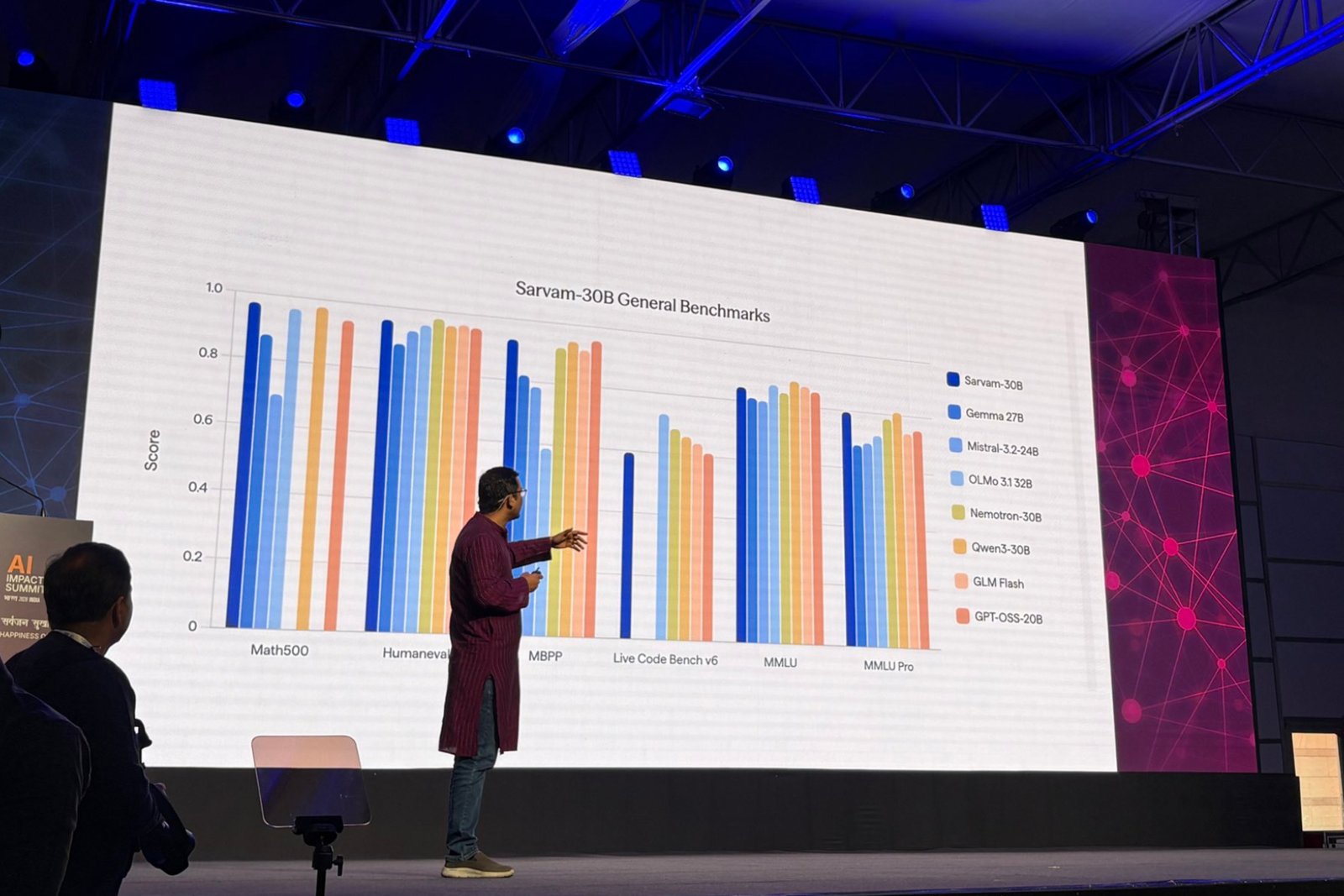
Sarvam said the new lineup includes 30-billion and 105-billion parameter models; a text-to-speech model; a speech-to-text model; and a vision model to parse documents. These mark a sharp upgrade from the company’s 2-billion-parameter Sarvam 1 model that it released in October 2024.
The 30-billion- and 105-billion-parameter models use a mixture-of-experts architecture, which activates only a fraction of their total parameters at a time, significantly reducing computing costs, Sarvam said. The 30B model supports a 32,000-token context window aimed at real-time conversational use, while the larger model offers a 128,000-token window for more complex, multi-step reasoning tasks.

Sarvam said the new AI models were trained from scratch rather than fine-tuned on existing open-source systems. The 30B model was pre-trained on about 16 trillion tokens of text, while the 105B model was trained on trillions of tokens spanning multiple Indian languages, it said.
The models are designed to support real-time applications, the startup said, including voice-based assistants and chat systems in Indian languages.

The startup said the models were trained using computing resources provided under India’s government-backed IndiaAI Mission, with infrastructure support from data center operator Yotta and technical support from Nvidia.
Techcrunch event
Boston, MA
|
June 23, 2026
Sarvam executives said the company plans to take a measured approach to scaling its models, focusing on real-world applications rather than raw size.

“We want to be mindful in how we do the scaling,” Sarvam co-founder Pratyush Kumar said at the launch. “We don’t want to do the scaling mindlessly. We want to understand the tasks which really matter at scale and go and build for them.”
Sarvam said it plans to open-source the 30B and 105B models, though it did not specify whether the training data or full training code would also be made public.
The company also outlined plans to build specialized AI systems, including coding-focused models and enterprise tools under a product it calls Sarvam for Work, and a conversational AI agent platform called Samvaad.
Founded in 2023, Sarvam has raised more than $50 million in funding and counts Lightspeed Venture Partners, Khosla Ventures and Peak XV Partners (formerly Sequoia Capital India) among its investors.






{kind=link}