


In recent years, computer scientists have created various highly performing machine learning tools to generate texts, images, videos, songs and other content. Most of these computational models are designed to create content based on text-based instructions provided by users.


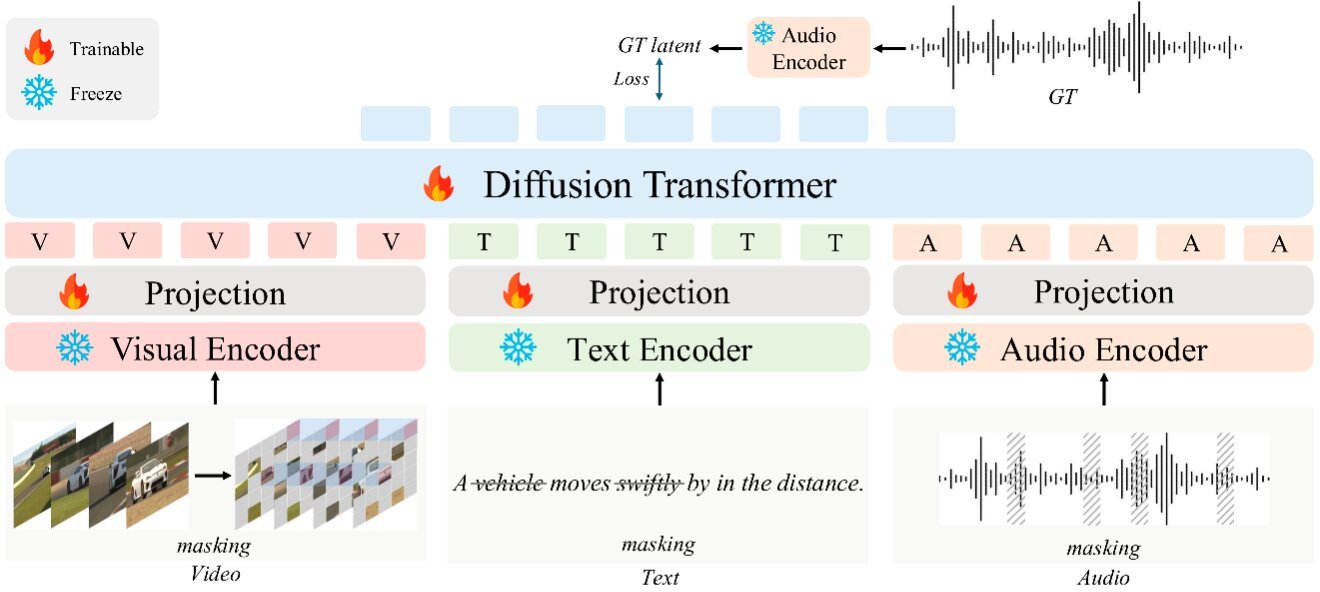
Researchers at the Hong Kong University of Science and Technology recently introduced AudioX, a model that can generate high quality audio and music tracks using texts, video footage, images, music and audio recordings as inputs. Their model, introduced in a paper published on the arXiv preprint server, relies on a diffusion transformer, an advanced machine learning algorithm that leverages the so-called transformer architecture to generate content by progressively de-noising the input data it receives.
“Our research stems from a fundamental question in artificial intelligence: how can intelligent systems achieve unified cross-modal understanding and generation?” Wei Xue, the corresponding author of the paper, told Tech Xplore. “Human creation is a seamlessly integrated process, where information from different sensory channels is naturally fused by the brain. Traditional systems have often relied on specialized models, failing to capture and fuse these intrinsic connections between modalities.”
The main goal of the recent study led by Wei Xue, Yike Guo and their colleagues was to develop a unified representation learning framework. This framework would allow an individual model to process information across different modalities (i.e., texts, images, videos and audio tracks), instead of combining distinct models that can only process a specific type of data.
“We aim to enable AI systems to form cross-modal concept networks similar to the human brain,” said Xue. “AudioX, the model we created, represents a paradigm shift, aimed at tackling the dual challenge of conceptual and temporal alignment. In other words, it is designed to address both ‘what’ (conceptual alignment) and ‘when’ (temporal alignment) questions simultaneously. Our ultimate objective is to build world models capable of predicting and generating multimodal sequences that remain consistent with reality.”
The new diffusion transformer-based model developed by the researchers can generate high-quality audio or music tracks using any input data as guidance. This ability to convert “anything” into audio opens new possibilities for the entertainment industry and creative professions. For example, allowing users to create music that fits a specific visual scene or use a combination of inputs (e.g., texts and videos) to guide the generation of desired tracks.
“AudioX is built on a diffusion transformer architecture, but what sets it apart is the multi-modal masking strategy,” explained Xue. “This strategy fundamentally reimagines how machines learn to understand relationships between different types of information.
“By obscuring elements across input modalities during training (i.e., selectively removing patches from video frames, tokens from text, or segments from audio), and training the model to recover the missing information from other modalities, we create a unified representation space.”

AudioX is one of the first models to combine linguistic descriptions, visual scenes and audio patterns, capturing the semantic meaning and rhythmic structure of this multi-modal data. Its unique design allows it to establish associations between different types of data, similarly to how the human brain integrates information picked up by different senses (i.e., vision, hearing, taste, smell and touch).
“AudioX is by far the most comprehensive any-to-audio foundation model, with various key advantages,” said Xue. “Firstly, it is a unified framework supporting highly diversified tasks within a single model architecture. It also enables cross-modal integration through our multi-modal masked training strategy, creating a unified representation space. It has versatile generation capabilities, as it can handle both general audio and music with high quality, trained on large-scale datasets including our newly curated collections.”
In initial tests, the new model created by Xue and his colleagues was found to produce high quality audio and music tracks, successfully integrating texts, videos, images and audio. Its most remarkable characteristic is that it does not combine different models, but rather utilizes a single diffusion transformer to process and integrate different types of inputs.
“AudioX supports diverse tasks in one architecture, ranging from text/video-to-audio to audio inpainting and music completion, advancing beyond systems that typically excel at only specific tasks,” said Xue. “The model could have various potential applications, spanning across film production, content creation and gaming.”
. DOI: 10.48550/arxiv.2503.10522")
AudioX could soon be improved further and deployed in a wide range of settings. For instance, it could assist creative professionals in the production of films, animations and content for social media.
“Imagine a filmmaker no longer needing a Foley artist for every scene,” explained Xue. “AudioX could automatically generate footsteps in snow, creaking doors or rustling leaves based solely on the visual footage. Similarly, it could be used by influencers to instantly add the perfect background music to their TikTok dance videos or by YouTubers to enhance their travel vlogs with authentic local soundscapes—all generated on-demand.”
In the future, AudioX could also be used by videogame developers to create immersive and adaptive games, in which background sounds dynamically adapt to the actions of players. For example, as a character moves from a concrete floor to grass, the sound of their footsteps could change, or the game’s soundtrack could gradually become more tense as they approach a threat or enemy.
“Our next planned steps include extending AudioX to long-form audio generation,” added Xue. “Moreover, rather than merely learning the associations from multimodal data, we hope to integrate human aesthetic understanding within a reinforcement learning framework to better align with subjective preferences.”
More information:
Zeyue Tian et al, AudioX: Diffusion Transformer for Anything-to-Audio Generation, arXiv (2025). DOI: 10.48550/arxiv.2503.10522
arXiv
© 2025 Science X Network
Citation:
New model can generate audio and music tracks from diverse data inputs (2025, April 14)
retrieved 15 April 2025
from https://techxplore.com/news/2025-04-generate-audio-music-tracks-diverse.html
This document is subject to copyright. Apart from any fair dealing for the purpose of private study or research, no
part may be reproduced without the written permission. The content is provided for information purposes only.






{kind=link}