


Among the many artificial intelligence and machine learning models available today for image translation, image-to-image translation models using Generative Adversarial Networks (GANs) can change the style of images.


These models work by using two input images: a content image, which is altered to match the style of a reference image. The models are used for tasks like transforming images into different artistic styles, simulating weather changes, improving satellite video resolution, and helping autonomous vehicles recognize different lighting conditions, like day and night.
Now, researchers from Sophia University have developed a model which can reduce the computational requirements needed to run these models, making it possible to run them on a wide range of devices, including smartphones.
In a study published in the IEEE Open Journal of the Computer Society on 25 September 2024, Project Assistant Professor Rina Oh and Professor Tad Gonsalves from the Department of Information and Communication Sciences at Sophia University proposed a “single-stream image-to-image translation (SSIT)” model that uses only a single encoder to carry out this transformation.
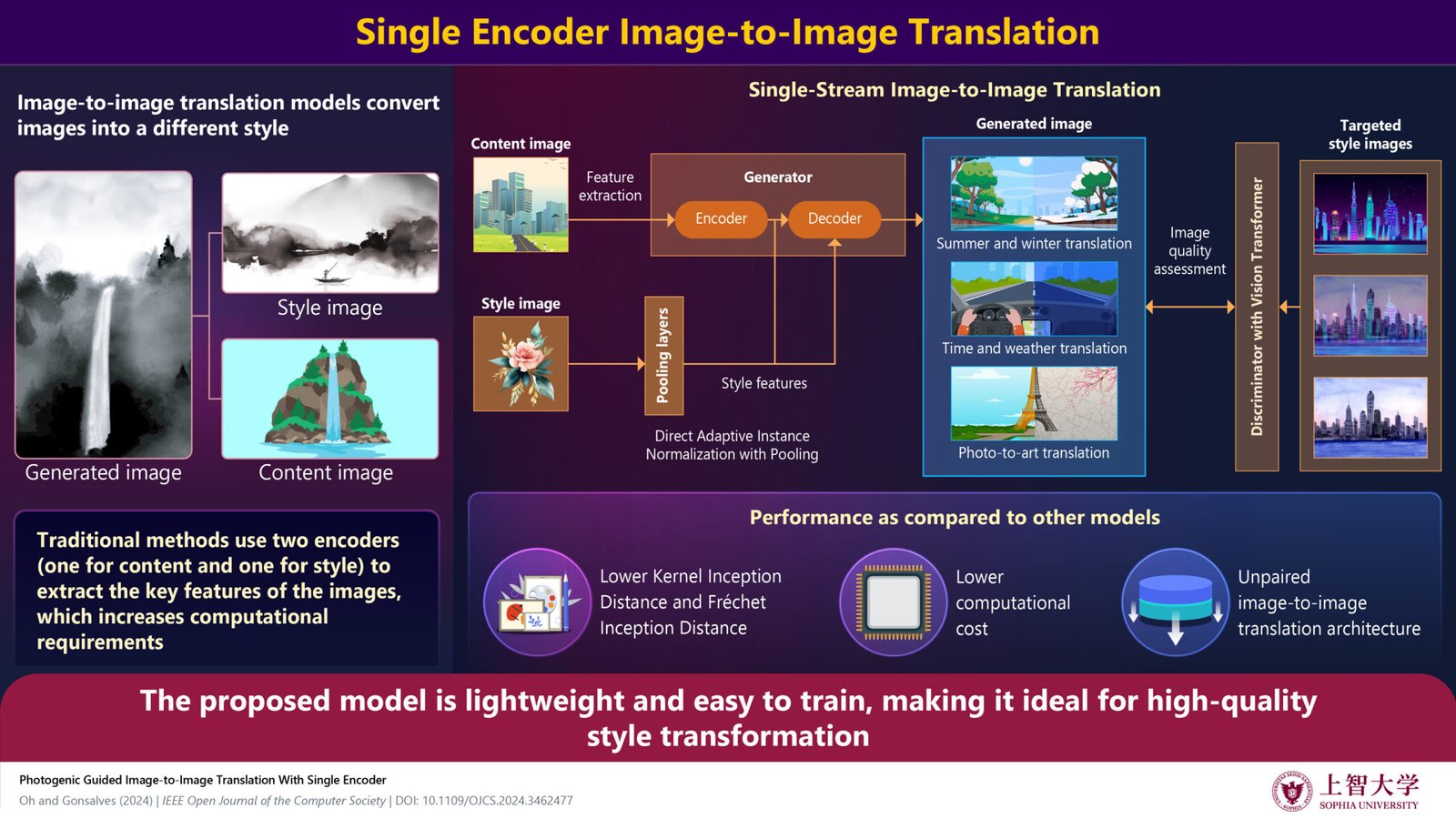
Typically, image-to-image translation models require two encoders—one for the content image and one for the style image—to “understand” the images.
These encoders convert the content and style images into numerical values (feature space) that represent key aspects of the image, such as color, objects, and other features. The decoder then takes the combined content and style features and reconstructs the final image with the desired content and style.
In contrast, SSIT uses a single encoder to extract spatial features such as the shapes, object boundaries, and layouts of the content image.
For the style image, the model uses Direct Adaptive Instance Normalization with Pooling (DAdaINP), which captures key style details like colors and textures while focusing on the most prominent features to improve efficiency. A decoder then takes the combined content and style features and reconstructs the final image with the desired content and style.
Prof. Oh says, “We implemented a guided image-to-image translation model that performs style transformation with reduced GPU computational costs while referencing input style images.
“Unlike previous related models, our approach utilizes Pooling and Deformable Convolution to efficiently extract style features, enabling high-quality style transformation with both reduced computational cost and preserved spatial features in the content images.”
, artistic style transformations (e.g., Monet and anime), and time/weather translations (e.g., day-to-night). Credit: R. Oh and T. Gonsalves / Sophia University, Japan. computer.org/csdl/journal/oj/2024/01/10694773/20wCWTplz7W")
The model is trained using adversarial training, where the generated images are evaluated by a Discriminator with a Vision Transformer, which captures patterns in images. The discriminator assesses whether the generated images are real or fake by comparing them to the target images, while the generator learns to create images that can fool the discriminator.
Using the model, the researchers performed three types of image transformation tasks. The first involved seasonal transformation, where landscape photos were converted from summer to winter and vice versa.
The second task was photo-to-art conversion, in which landscape photos were transformed into famous artistic styles, such as those of Picasso, Monet, or anime.
The third task focused on time and weather translation for driving, where images captured from the front of a car were altered to simulate different conditions, such as changing from day to night or from sunny to rainy weather.
In all these tasks, the model performed better than five other GAN models (namely NST, CNNMRF, MUNIT, GDWCT, and TSIT), with lower Fréchet Inception Distance and Kernel Inception Distance scores. This demonstrates that the generated images were similar to the target styles and did a better job of replicating colors and artistic details.
“Our generator was able to reduce the computational cost and FLOPs compared to the other models because we employed a single encoder that consists of multiple convolution layers only for content image and placed pooling layers for extracting style features at different angles instead of convolution layers,” says Prof. Oh.
In the long run, the SSIT model has the potential to democratize image transformation, making it deployable on devices like smartphones or personal computers.
It enables users across various fields, including digital art, design, and scientific research, to create high-quality image transformations without relying on expensive hardware or cloud services.
More information:
Rina Oh et al, Photogenic Guided Image-to-Image Translation With Single Encoder, IEEE Open Journal of the Computer Society (2024). DOI: 10.1109/OJCS.2024.3462477
Sophia University
Citation:
Single-stream model enhances image translation efficiency (2024, December 16)
retrieved 16 December 2024
from https://techxplore.com/news/2024-12-stream-image-efficiency.html
This document is subject to copyright. Apart from any fair dealing for the purpose of private study or research, no
part may be reproduced without the written permission. The content is provided for information purposes only.






{kind=link}