
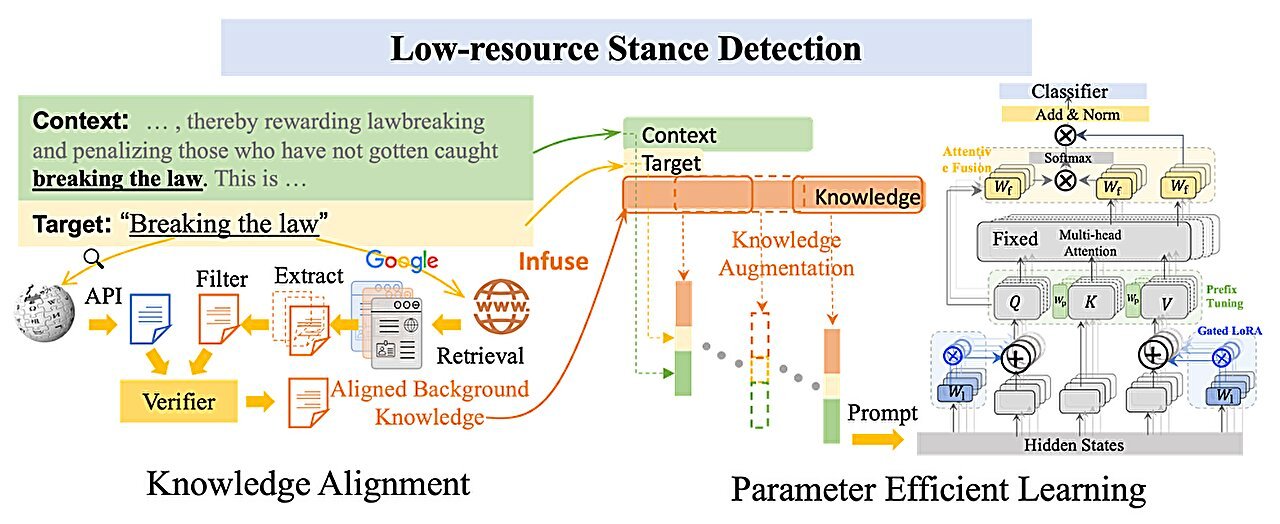
 and learn features more efficiently (parameter efficient learning) to improve the accuracy and training of AI models with smaller training datasets. Credit: Big Data Mining and Analytics, Tsinghua University Press")
General AI systems, like OpenAI’s GPT, depend on large amounts of training data to improve model accuracy and performance. Research or medical AI applications, which often lack both training data and computing power, can leverage a new model designed to improve the efficiency, relevance and accuracy of AI outputs for more specialized scenarios.


Large pretrained language models (PLMs) use increasingly large datasets, like Wikipedia, to train and optimize machine learning (ML) models to perform a specific task. While the accuracy and performance of large PLMs, like ChatGPT, have improved over time, large PLMs don’t work well in situations where large datasets aren’t available or can’t be used due to computing limitations.
Simply put, a new AI solution is required to effectively utilize ML in research, medical or other applications where vast amounts of information aren’t available to adequately train existing AI models.
To address this issue, a team of computer scientists from the Agency for Science Technology and Research (A*STAR) in Singapore recently engineered a collaborative knowledge infusion method that efficiently trains an ML model with smaller amounts of training data. In this case, the researchers created a model that more accurately determines the stance, or opinion for or against, of a specific target, such as a product or political candidate, based on the context of a Tweet, commercial review or other language data.
The team published their study in the journal Big Data Mining and Analytics on August 28.
“Stance detection is inherently a low-resource task due to the diversity of targets and the limited availability of annotated data. Despite these challenges, stance detection is critical for monitoring social media, conducting polls and informing governance strategies,” said Yan Ming, senior scientist at the Center for Frontier AI Research (CFAR) at A*STAR and first author of the paper. “Enhancing AI-based methods for low-resource stance detection is essential to ensure these tools are effective and reliable in real-world applications.”
Smaller training datasets can have a profound effect on the accuracy of AI prediction models. For example, the target “breaking the law” in Wikipedia links to a heavy metal song by Judas Priest rather than the true definition of the term: acting in an illegal manner. This type of erroneous training data can seriously affect the performance of ML models.
In order to improve the accuracy of AI stance detection that depends on smaller training datasets, the research team focused on collaborative model mechanisms to: verify knowledge from different sources and learn selective features more efficiently.
“Most AI systems rely on pre-trained models developed using massive, pre-defined datasets that can become outdated, leading to performance degradation. Our proposed method addresses this challenge by integrating verified knowledge from multiple sources, ensuring that the model remains relevant and effective,” said Ming.
“Pre-trained large language models additionally require extensive annotated data for training due to their large-scale parameters. Our method introduces a collaborative adaptor that incorporates a minimal number of trainable parameters, … enhancing training efficiency and improving feature learning capabilities,” said Ming.
The team also targeted optimization efficiency of large PLMs by staging the optimization algorithm.
To test their model, the researchers performed experiments on three publicly available stance-detection datasets: VAST, P-Stance and COVID-19-Stance. The performance of the team’s model was then compared to the performance achieved by the TAN, BERT, WS-BERT-Dual and other AI models.
Measured through F1 scores, an ML model accuracy, the research team’s new stance detection model for low-resource training data consistently scored higher than other AI models using all three datasets, with F1 scores of between 79.6% and 86.91%. An F1 score of 70% or higher is currently considered good.
The new stance-detection model greatly improves the practicality of AI in more specialized research settings, and provides a template for additional optimization in the future.
“Our primary focus is on efficient learning within low-resource real-world applications. Unlike major AI firms that concentrate on developing general artificial intelligence (AGI) models, our objective is to create more efficient AI methods that benefit both the public and the research community,” said Joey Tianyi Zhou, principal scientist at CFAR and co-author of the paper.
Ivor W. Tsang from the Centre for Frontier AI Research (CFAR) and the Institute of High Performance Computing (IHPC) at the Agency for Science Technology and Research (A*STAR) in Singapore also contributed to this research.
More information:
Ming Yan et al, Collaborative Knowledge Infusion for Low-Resource Stance Detection, Big Data Mining and Analytics (2024). DOI: 10.26599/BDMA.2024.9020021
Provided by
Tsinghua University Press
Citation:
New AI learning model improves stance detection performance and efficiency (2024, September 3)
retrieved 3 September 2024
from https://techxplore.com/news/2024-09-ai-stance-efficiency.html
This document is subject to copyright. Apart from any fair dealing for the purpose of private study or research, no
part may be reproduced without the written permission. The content is provided for information purposes only.





{kind=link}